什么时候该使用 MQ、Redis 和 配置中心
究竟什么时候该使用 MQ? https://mp.weixin.qq.com/s/_kXoRBAotb4GXoDTqTObYQ
架构选型,究竟啥时候选 Redis? https://mp.weixin.qq.com/s/aX60hdFeuOTW8i3KG_CrtA
互联网架构,究竟为什么需要配置中心? https://mp.weixin.qq.com/s/k1IVjya7qtIf8jwWqTumjA
究竟什么时候该使用 MQ?
**任何脱离业务的组件引入都是耍流氓。**引入一个组件,最先该解答的问题是,此组件解决什么问题。
MQ,互联网技术体系中一个常见组件,究竟什么时候不使用 MQ,究竟什么时候使用 MQ,MQ 究竟适合什么场景,是今天要分享的内容。
MQ 是什么?
消息总线(Message Queue),后文称 MQ,是一种跨进程的通信机制,用于上下游传递消息。
画外音:这两个进程,一般不在同一台服务器上。
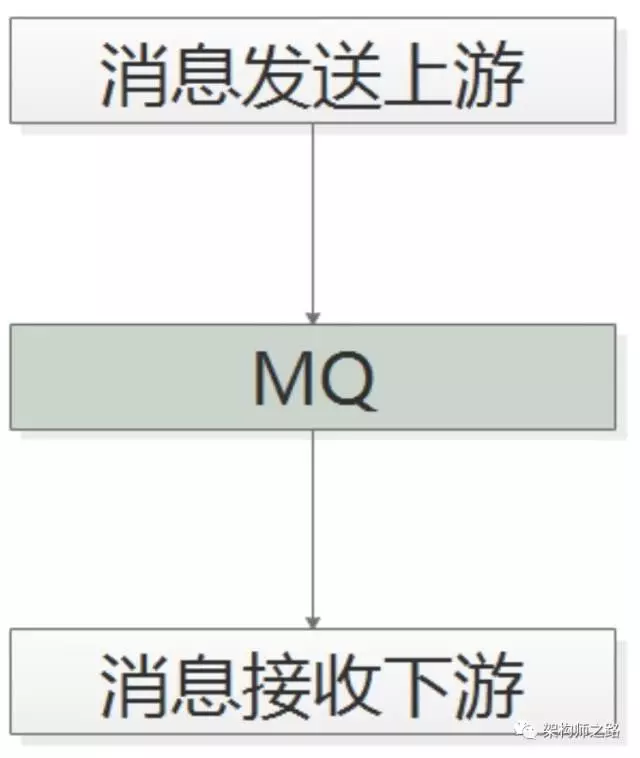
在互联网架构中,MQ 经常用做“上下游解耦”:
(1)消息发送方只依赖 MQ,不关注消费方是谁;
(2)消息消费方也只依赖 MQ,不关注发送方是谁。
画外音:发送方与消费方,逻辑上和物理上都不依赖彼此。
什么时候不使用 MQ?
当调用方需要关心消息执行结果时,通常不使用 MQ,而使用 RPC 调用。
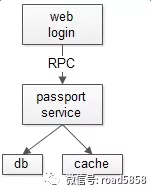
1 | ret = PassportService::userAuth(name, pass); |
如上例所示,上游调用 Passport 服务,处理结果不同,业务会走不同的逻辑处理分支(登录成功,登录失败,执行错误等),即“处理结果强依赖”,此时应该使用 RPC 调用。
画外音:绝大部分情况,应该使用 RPC。
此时如果强行使用 MQ 呢?
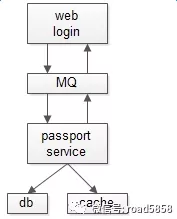
如果强行使用 MQ 通讯,调用方不能直接告之用户登录成功又或失败,则要等待另一个 MQ 通知回调。这么玩,不但使得编码复杂,还会引入消息丢失的风险,中间多加入一层,多此一举。
究竟什么时候使用 MQ 呢?
下面四类典型场景,应该使用 MQ。
典型场景一:数据驱动的任务依赖
什么是任务依赖?
举个栗子,互联网公司经常在凌晨进行一些数据统计任务,这些任务之间有一定的依赖关系,例如:
(1)task3 需要使用 task2 的输出作为输入;
(2)task2 需要使用 task1 的输出作为输入。
这样的话,tast1, task2, task3之间就有任务依赖关系,必须 task1 先执行,再 task2 执行,再 task3 执行。
对于这类需求,通常怎么实现呢?
常见的玩法是,crontab 人工排执行时间表。
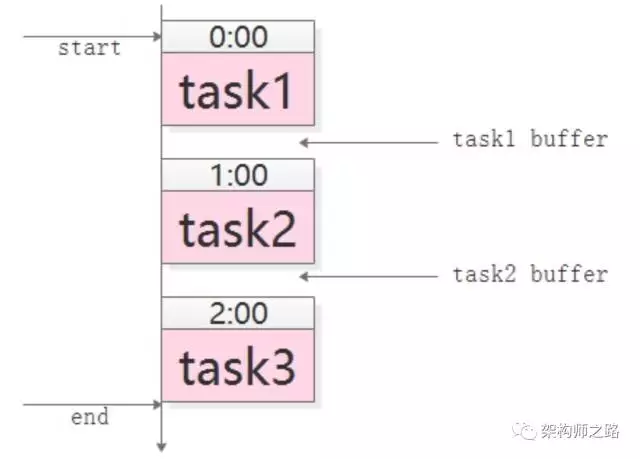
如上图,手动设定如下:
(1)task1,0:00 执行,经验执行时间为 50 分钟;
(2)task2,1:00 执行(为 task1 预留 10 分钟 buffer),经验执行时间也是 50 分钟;
(3)task3,2:00 执行(为 task2 预留 10 分钟 buffer)。
crontab 手动排表有什么坏处呢?
(1)如果有一个任务执行时间超过了预留 buffer 的时间,将会得到错误的结果,因为后置任务不清楚前置任务是否执行成功,此时要手动重跑任务,还有可能要调整排班表;
(2)总任务的执行时间很长,总是要预留很多 buffer,如果前置任务提前完成,后置任务不会提前开始;
(3)如果一个任务被多个任务依赖,这个任务将会称为关键路径,排班表很难体现依赖关系,容易出错;
(4)如果有一个任务的执行时间要调整,将会有多个任务的执行时间要调整。
无论如何,采用 “crontab 排班表” 的方法,各任务严重耦合,谁用过谁痛谁知道。
应该如何优化呢?
采用 MQ 解耦。
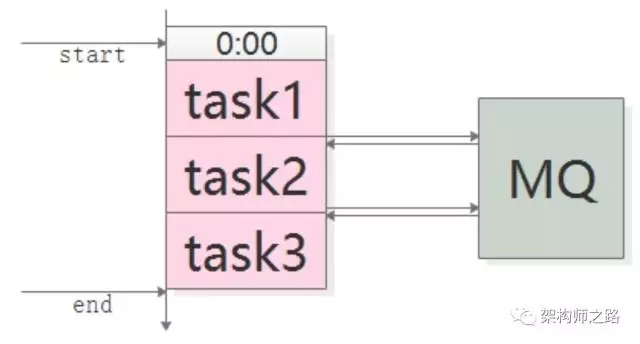
如上图,任务之间通过 MQ 来传递“开始”与“结束”的通知:
(1)task1 准时开始,结束后发一个 “task1 done” 的消息;
(2)task2 订阅 “task1 done” 的消息,收到消息后第一时间启动执行,结束后发一个 “task2 done” 的消息;
(3)task3 同理。
采用 MQ 有什么好处呢?
(1)不需要预留 buffer,上游任务执行完,下游任务总会在第一时间被执行;
(2)依赖多个任务,被多个任务依赖都很好处理,只需要订阅相关消息即可;
(3)有任务执行时间变化,下游任务都不需要调整执行时间。
需要特别说明的是,MQ 只用来传递上游任务执行完成的消息,并不用于传递真正的输入输出数据。
典型场景二:上游不关心执行结果
上游需要关注执行结果时要用 “RPC 调用”,上游不关注执行结果时,使用 MQ。
举个栗子,58 同城的很多下游需要关注“用户发布帖子”这个事件,比如:
(1)招聘用户发布帖子后,招聘业务要奖励 58 豆;
(2)房产用户发布帖子后,房产业务要送 2 个置顶;
(3)二手用户发布帖子后,二手业务要修改用户统计数据。
对于这类需求,可以采用什么方式实现呢?
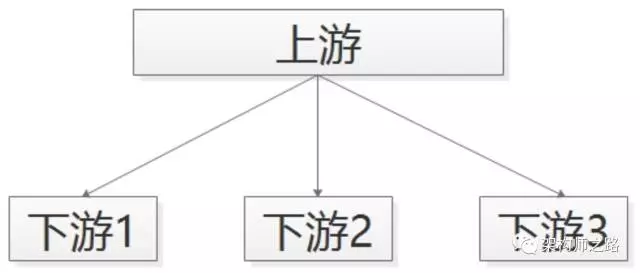
比较无脑的,可以使用 RPC 调用来实现:
帖子发布服务执行完成之后,调用下游招聘业务、房产业务、二手业务,来完成消息的通知。
但事实上,这个通知是否正常正确的执行,帖子发布服务根本不关注。
通过 RPC 来传递不需要知道处理结果的通知,有什么坏处呢?
(1)帖子发布流程的执行时间增加了;
(2)下游服务当机,可能导致帖子发布服务受影响,上下游逻辑+物理依赖严重;
(3)每当增加一个需要知道“帖子发布成功”信息的下游,修改代码的是帖子发布服务。
画外音:这一点是最恶心的,属于架构设计中典型的反向依赖。
如何来进行优化呢?
采用 MQ 解耦,代替 RPC。
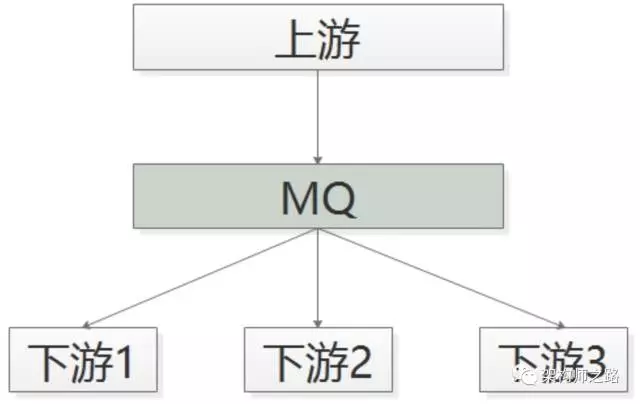
如上图所示:
(1)帖子发布成功后,向 MQ 发一个消息;
(2)哪个下游关注“帖子发布成功”的消息,主动去 MQ 订阅。
如此一来,有什么好处呢?
(1)上游执行时间短;
(2)上下游逻辑+物理解耦,除了与 MQ 有物理连接,模块之间都不相互依赖;
(3)新增一个下游消息关注方,上游不需要修改任何代码。
典型场景三:上游关注执行结果,但执行时间很长
有时候上游需要关注执行结果,但执行结果时间很长(典型的是调用离线处理,或者跨公网调用),也经常使用 回调网关 + MQ 来解耦。
举个栗子,微信支付,跨公网调用微信的接口,执行时间会比较长,但调用方又非常关注执行结果,此时一般怎么玩呢?
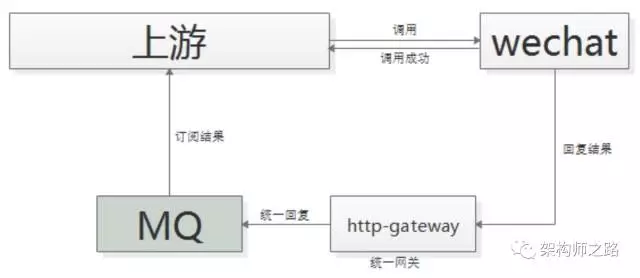
一般采用 “回调网关 + MQ” 方案来解耦:
(1)调用方直接跨公网调用微信接口;
(2)微信返回调用成功,此时并不代表返回成功;
(3)微信执行完成后,回调统一网关;
(4)网关将返回结果通知 MQ;
(5)请求方收到结果通知。
这里需要注意的是,不应该由回调网关来 RPC 通知上游来通知结果,如果是这样的话,每次新增调用方,回调网关都需要修改代码,仍然会反向依赖,使用 回调网关 + MQ 的方案,新增任何对微信支付的调用,都不需要修改代码。
结尾总结
MQ 是一个互联网架构中常见的解耦利器。
什么时候不使用 MQ?
上游实时关注执行结果,通常采用 RPC。
什么时候使用 MQ?
(1)数据驱动的任务依赖;
(2)上游不关心多下游执行结果;
(3)异步返回执行时间长。
架构选型,究竟啥时候选 Redis?
Redis 是互联网分层架构中,最常用的 KV 缓存,但不少同学仍然不知道,为啥要选择 Redis。
画外音:与之对比最多的,是 memcache。
一、复杂数据结构,选择 Redis 更合适
value 是哈希,列表,集合,有序集合这类复杂的数据结构时,会选择 Redis,因为 mc 无法满足这些需求。
最典型的场景,用户订单列表,用户消息,帖子评论列表等。
二、持久化,选择 Redis 更合适
mc 无法满足持久化的需求,只得选择 Redis。
但是,这里要提醒的是,真的使用对了 Redis 的持久化功能么?
千万不要把 Redis 当作数据库用:
(1)Redis 的定期快照不能保证数据不丢失;
(2)Redis 的 AOF 会降低效率,并且不能支持太大的数据量。
不要期望 Redis 做固化存储会比 MySQL 做得好,不同的工具做各自擅长的事情,把 Redis 当作数据库用,这样的设计八成是错误的。
缓存场景,开启固化功能,有什么利弊?
如果只是缓存场景,数据存放在数据库,缓存在 Redis,此时如果开启固化功能:
优点是,Redis 挂了再重启,内存里能够快速恢复热数据,不会瞬时将压力压到数据库上,没有一个 cache 预热的过程。
缺点是,在 Redis 挂了的过程中,如果数据库中有数据的修改,可能导致 Redis 重启后,数据库与 Redis 的数据不一致。
因此,只读场景,或者允许一些不一致的业务场景,可以尝试开启 Redis 的固化功能。
三、高可用,选择 Redis 更合适
Redis 天然支持集群功能,可以实现主动复制,读写分离。
Redis 官方也提供了 sentinel 集群管理工具,能够实现主从服务监控,故障自动转移,这一切,对于客户端都是透明的,无需程序改动,也无需人工介入。
画外音:memcache,要想要实现高可用,需要进行二次开发,例如客户端的双读双写,或者服务端的集群同步。
但是,这里要提醒的是,大部分业务场景,缓存真的需要高可用么?
(1)缓存场景,很多时候,是允许 cache miss;
(2)缓存挂了,很多时候可以通过 DB 读取数据。
所以,需要认真剖析业务场景,高可用,是否真的是对缓存的主要需求?
画外音:即时通讯业务中,用户的在线状态,就有高可用需求。
四、存储的内容比较大,选择 Redis 更合适
memcache 的 value 存储,最大为 1M,如果存储的 value 很大,只能使用 Redis。
当然,Redis 与 memcache 相比,由于底层实现机制的差异,也有一些“劣势”的情况。
情况一:由于内存分配机制的差异,Redis 可能导致内存碎片
memcache 使用预分配内存池的方式管理内存,能够省去内存分配时间。
Redis 则是临时申请空间,可能导致碎片。
从这一点上,mc会更快一些。
情况二:由于虚拟内存使用的差异,Redis 可能会刷盘影响性能
memcache 把所有的数据存储在物理内存里。
Redis 有自己的 VM 机制,理论上能够存储比物理内存更多的数据,当数据超量时,会引发 swap,把冷数据刷到磁盘上。
从这一点上,数据量大时,mc 会更快一些。
画外音:新版本 Redis 已经优化。
情况三:由于网络模型的差异,Redis 可能会因为 CPU 计算影响 IO 调度
memcache 使用非阻塞 IO 复用模型,Redis 也是使用非阻塞 IO 复用模型。
但由于 Redis 还提供一些非 KV 存储之外的排序,聚合功能,在执行这些功能时,复杂的 CPU 计算,会阻塞整个 IO 调度。
从这一点上,由于 Redis 提供的功能较多,mc 会更快一些。
情况四:由于线程模型的差异,Redis 难以利用多核特效提升性能
memcache 使用多线程,主线程监听,worker 子线程接受请求,执行读写,这个过程中,可能存在锁冲突。
Redis 使用单线程,虽无锁冲突,但难以利用多核的特性提升整体吞吐量。
从这一点上,mc 会快一些。
情况五:由于缺乏 auto-sharding,Redis 只能手动水平扩展
不管是 Redis 还是 memcache,服务端集群没有天然支持水平扩展,需要在客户端进行分片,这其实对调用方并不友好。如果能服务端集群能够支持水平扩展,会更完美一些。
互联网架构,究竟为什么需要配置中心?
配置中心是互联网架构体系中很重要的一块,但为什么会有配置中心,是不是一开始就要有配置中心,它究竟解决什么问题,这是今天要讨论的问题。
随着互联网业务的越来越复杂,用户量与流量越来越大,“服务化分层”是架构演进的必由之路。
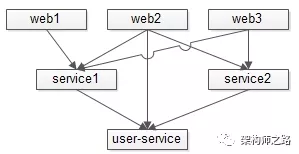
如上图,站点应用会调用服务,上游服务调用底层服务,依赖关系会变得非常复杂。
对于同一个服务:
(1)它往往有多个上游调用;
(2)为了保证高可用,它往往是若干个节点组成的集群提供服务。
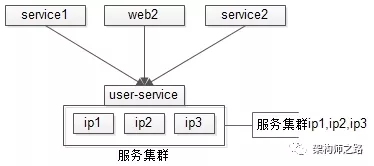
如上图,用户中心服务 user-service 有三个节点,ip1/ip2/ip3 对上游提供服务,任何一个节点当机,都不影响服务的可用性。
那么问题来了:
- 调用方如何维护下游服务集群配置?
- 当服务集群增减节点时,调用方是否有感知?
初期:“配置私藏”架构
“配置私藏”是配置的最初级阶段,上游调用下游,每个上游都有一个专属的私有配置文件,记录被调用下游的每个节点配置信息。
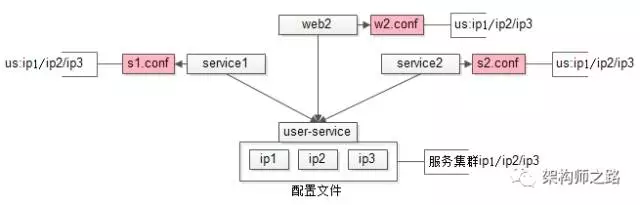
如上图:
(1)用户中心 user-service 有 ip1/ip2/ip3 三个节点;
(2)service1 调用了用户中心,它有一个专属配置文件 s1.conf,里面配置了 us 的集群是 ip1/ip2/ip3;
(3)service2 也调用了用户中心,同理有个配置文件 s2.conf,记录了 us 集群是 ip1/ip2/ip3;
(4)web2 也调用了用户中心,同理 w2.conf,配置了 us 集群是 ip1/ip2/ip3。
画外音:是不是很熟悉?绝大部分公司,初期都是这么玩的。
“配置私藏”架构的缺点是什么呢?
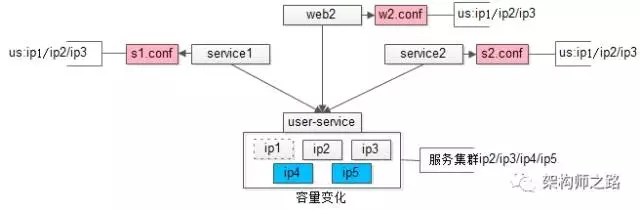
来看一个容量变化的需求:
(1)运维检测出 ip1 节点的硬盘性能下降,通知研发未来要将 ip1 节点下线;
(2)由于 5 月 8 日要做大促运营活动,未来流量会激增,研发准备增加两个节点 ip4 和 ip5。
此时要怎么做呢?
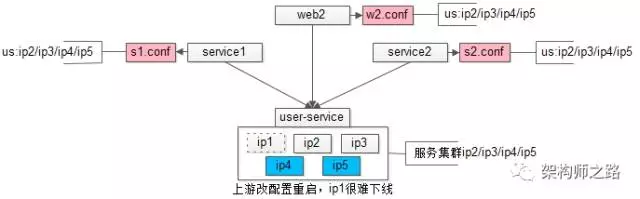
需要用户中心的负责人通知所有上游调用者,修改“私藏”的配置,并重启上游,连接到新的集群上去。在 ip1 上没有流量之后,通知运维将 ip1 节点下线,以完成整个缩容扩容过程。
这种方案存在什么问题呢?
当业务复杂度较高,研发人数较多,服务依赖关系较复杂的时候,就没这么简单了。
问题一:调用方很痛,容量变化的是你,凭啥修改配置重启的是我?这是一个典型的“反向依赖”架构设计,上下游通过配置耦合,不合理。
问题二:服务方很痛,ta 不知道有多少个上游调用了自己,往往只能通过以下方式来定位上游:
(1)群里吼
(2)发邮件询问
(3)通过连接找到 ip,通过 ip 问运维,找到机器负责人,再通过机器负责人找到对应调用服务
画外音:是不是似曾相识?
不管哪种方式,都很有可能遗漏,导致 ip1 一直有流量难以下线,ip4/ip5 的流量难以均匀迁移过来。该如何优化呢?
中期:“全局配置”架构
架构的升级并不是一步到位的,先来用最低的成本来解决上述“修改配置重启”的问题一。
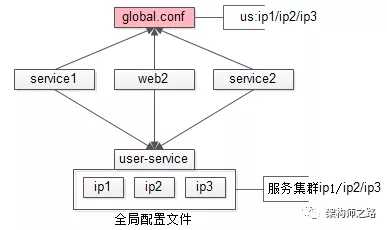
“全局配置”架构:对于通用的服务,建立全局配置文件,消除配置私藏:
(1)运维层面制定规范,新建全局配置文件,例如 /opt/global.conf;
画外音:如果配置较多,注意做好配置的垂直拆分。
(2)对于服务方,如果是通用的服务,集群信息配置在 global.conf 里;
(3)对于调用方,调用方禁止配置私藏,必须从 global.conf 里读取通用下游配置。
全局配置有什么好处呢?
(1)如果下游容量变化,只需要修改一处配置 global.conf,而不需要各个上游修改;
(2)调用方下一次重启的时候,自动迁移到扩容后的集群上来了;
(3)修改成本非常小,读取配置文件目录变了而已。
全局配置有什么不足呢?
如果调用方一直不重启,就没有办法将流量迁移到新集群上去了。
有没有方面实现自动流量迁移呢?
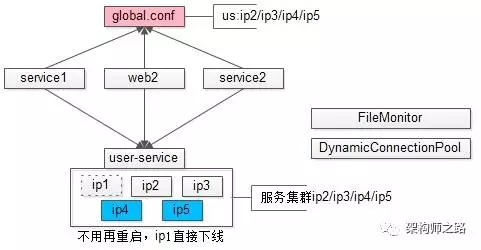
答案是肯定的,只需要引入两个并不复杂的组件,就能实现调用方的流量自动迁移:
(1)文件监控组件 FileMonitor
作用是监控文件的变化,起一个 timer,定期监控文件的 ModifyTime 或者 md5 就能轻松实现,当文件变化后,实施回调。
(2)动态连接池组件 DynamicConnectionPool
“连接池组件”是 RPC-client 中的一个子组件,用来维护与多个 RPC-server 节点之间的连接。所谓“动态连接池”,是指连接池中的连接可以动态增加和减少。
画外音:用锁来互斥,很容易实现。
引入了这两个组件之后:
(1)一旦全局配置文件变化,文件监控组件实施回调;
(2)如果动态连接池组件发现配置中减少了一些节点,就动态的将对应连接销毁,如果增加了一些节点,就动态建立连接,自动完成下游节点的增容与缩容。
终版:“配置中心”架构
“全局配置”架构是一个能够快速落地的,解决“修改配置重启”问题的方案,但它仍然解决不了,服务提供方“不知道有多少个上游调用了自己”这个问题。
如果不知道多少上游调用了自己:
(1)“按照调用方限流”
(2)“绘制全局架构依赖图”
等这类需求便难以实现,怎么办?
“配置中心”架构能够完美解决。
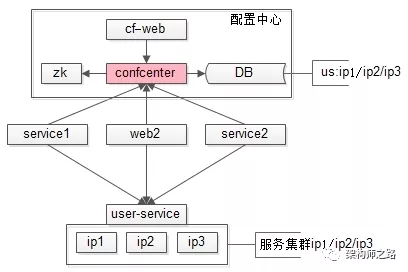
对比“全局配置”与“配置中心”的架构图,会发现配置由静态的文件升级为动态的服务:
(1)整个配置中心子系统由 zk、conf-center 服务,DB 配置存储与,conf-web 配置后台组成;
(2)所有下游服务的配置,通过后台设置在配置中心里;
(3)所有上游需要拉取配置,需要去配置中心注册,拉取下游服务配置信息(ip1/ip2/ip3)。
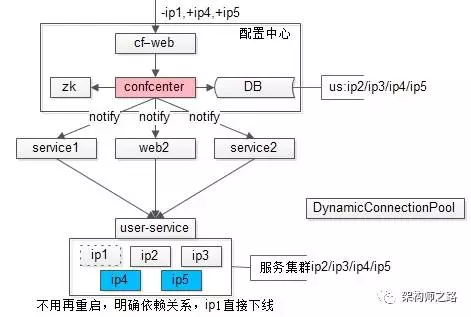
当下游服务需要扩容缩容时:
(1)conf-web 配置后台进行设置,新增 ip4/ip5,减少 ip1;
(2)conf-center 服务将变更的配置推送给已经注册关注相关配置的调用方;
(3)结合动态连接池组件,完成自动的扩容与缩容。
“配置中心”架构有什么好处呢?
(1)调用方不需要再重启;
(2)服务方从配置中心中很清楚的知道上游依赖关系,从而实施按照调用方限流;
(3)很容易从配置中心得到全局架构依赖关系。
痛点一、痛点二同时解决。
“配置中心”架构有什么不足呢?
一来,系统复杂度相对较高;
二来,对配置中心的可靠性要求较高,一处挂全局挂。
总结
究竟要解决什么痛点?
上游痛:扩容的是下游,改配置重启的是上游;
下游痛:不知道谁依赖于自己;
总之,难以实施服务治理。
究竟如何解决上述痛点?
一、“配置私藏”架构;
二、“全局配置文件”架构;
三、“配置中心”架构。